 Black Hole SEO, large popular websites are all jumping on the Internal Linking optimization strategy using aggregator pages for all stories on the topic, usually companies. This is either done in plain site, or through a bunch of Hidden Internal links within the content, using CSS to make these links appear as normal text. Only a mouse over will trigger an affect that shows the word is actually a link.
Black Hole SEO, large popular websites are all jumping on the Internal Linking optimization strategy using aggregator pages for all stories on the topic, usually companies. This is either done in plain site, or through a bunch of Hidden Internal links within the content, using CSS to make these links appear as normal text. Only a mouse over will trigger an affect that shows the word is actually a link.
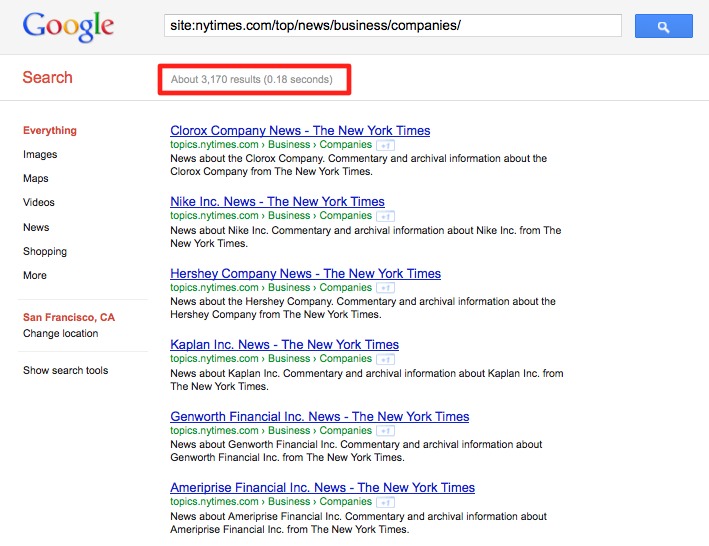
For one of the worse offenders in Black Hole SEO, just check any story by the New York Times on a large tech company, they don’t link to the website of Apple, eBay or Google, but rather link to the page which aggregates all the NYTimes stories on those companies. This way, The New York Times has added more than 3,000 pages into Google which do not add a lot of value other than the information which is probably available on the corporate websites of these companies already. As was mentioned by SEObook here: “The New York Times, seems reluctant to link to anyone but themselves. This is especially annoying when they write about websites. ”
Screenshot on the right: New York Times company aggregator pages indexed by Google, currently more than 3,000 pages indexed.
Although I would rather see The New York Times link out to the companies they are writing about, I can see the need for the Newspaper to drive more pageviews for its survival. At least The NYTimes is using visible links where everybody can see their Black Hole SEO strategy.
Hidden Internal Links for the WIN; Ultimate Black Hole SEO
When reading Techmeme, I came across a story on a popular tech & business media site, which is using the Black Hole SEO strategy, but hides their internal links from the public. While these links do not fall under the definition of hidden links in the Webmaster Guidelines from Google, I wonder why the internal links to the aggregator pages are hidden with css, instead of just being in plain sight for any of the users. The Google webmaster guidelines say this about hidden links (emphasis is mine):
Hidden links are links that are intended to be crawled by Googlebot, but are unreadable to humans because:
- The link consists of hidden text (for example, the text color and background color are identical).
- CSS has been used to make tiny hyperlinks, as little as one pixel high.
- The link is hidden in a small character – for example, a hyphen in the middle of a paragraph.
If your site is perceived to contain hidden text and links that are deceptive in intent, your site may be removed from the Google index, and will not appear in search results pages. When evaluating your site to see if it includes hidden text or links, look for anything that’s not easily viewable by visitors of your site. Are any text or links there solely for search engines rather than visitors?
Here is a screenshot of the source code of the site (I removed the actual domain name of the website):

In total 9 different hidden links to internal aggregation pages about companies or technology platforms or products. These include (in order of appearance):
- Android
- iPhone
- iOS
- Samsung
- iPhone 5
- Motorola
Completely makes sense. Great point, and it kind of makes sense of when and how big websites become brands, when people are naturally talking about them, writing about them and linking to them. Nature of the internet. Big sites should not be worried about linking out to known brands, websites etc. I understand the concern when talking about a cookie cutter website, bad neighborhoods etc. In that scenario, rel=nofollow, _blank should do the trick. But then what if that website closes, site changes etc, 404, then it’s a bad user experience for the linking website’s users.
@Nakul,
Thanks for your comment.
You can easily use a program like Xenu LinkSleuth or Integrity to check of link rot.
As soon as any of your external links give you a 404, you either remove the link, or set up a new destination for the link.
This should be the normal maintenance for any large media website.
Even if it’s a lot of work, I personally think it’s a worse user experience if I need to go look for the original source of a story, than when I can simply click on a link within the story. I would be ok if that site opens a new window, if the website is afraid of loosing readers.
Absolutely. It’s clearly not a great user experience to see all stories for Apple, Google, eBay etc when clicking on that link, when you actually expect that to go to a particular website, source etc. I have seen that happen several times myself when browsing around, reading news etc.
This is definitely not a SEO best-practice, but over optimization efforts. Controlling the flow of link juice.
@Nakul,
What’s more, flowing Juice using links hidden with CSS is in my book a clever but deceiving practice.
Pageview journalism; keep the users on the site *no matter what*
I have a number of sites that are quoted and excerpted on news sites all the time. Almost *none* of them will put an actual live link to me – the most I will get is a citation which is not clickable.
This is also true of media sites such as for radio and tv stations.
They do not want you to leave their site or risk missing even the smallest bit of ad revenue.
I had a managing editor of a major television news website try to tell me it’s because they couldn’t vouch for the veracity of the site, but when pressed, she admitted that she was ordered not to link to *anyone* as a matter of policy.